NTT Comが、IOWN APNを活用した分散データセンタでの生成AI学習実証実験に世界で初めて成功
DX/IoT/AI 無料NTTコミュニケーションズ(以下、NTT Com)は10月7日、超高速かつ超低消費電力を実現するIOWN構想の主要技術であるオールフォトニクス・ネットワーク(以下、APN)で接続した複数のデータセンタにNVIDIA GPU搭載サーバを分散配置した環境で、NVIDIA AI Enterprise プラットフォームの一部であるNVIDIA NeMoを用いた生成AIモデル学習の実証実験(以下、本実証)に世界で初めて成功したと発表した。
背景
生成AI、データ利活用、画像処理などの分野でGPUクラスタの重要性が高まる中、サービス提供事業者や利用者にとって従来は単一のデータセンタ内でGPUクラスタを構築・利用することが一般的だった。しかし、単一のデータセンタでは、生成AIのモデルサイズ増大に伴う処理量の変動に応じてオンデマンドにGPUリソースを入手できないことや、1拠点のデータセンタのキャパシティや電力供給に制限があること、利用者の拠点から移動できない機密度の高いデータの取り扱いが難しいことが課題だった。
NTT Comは「本実証により、IOWN APNを用いた分散データセンタにおける、GPUクラスタでの処理の有効性を確認することで、GPUクラスタ利用者や提供事業者の課題解決に貢献する」としている。
本実証の概要
NVIDIA GPU搭載サーバを約40km離れた三鷹と秋葉原のデータセンタに分散配置し、データセンタ間を100Gbps回線のIOWN APNで接続した。NVIDIA NeMoを使用して、両拠点のGPUサーバを連携させ、生成AIモデルの分散学習を実施した。
本実証はデル・テクノロジーズによるGPUサーバやストレージなどの機器提供および協力のもとで実施されたという。
本実証で用いられた技術の主な特長は以下の通り。
・IOWN APN
IOWN APNの高速大容量・低遅延接続により、GPUサーバ間のデータ転送が迅速かつ効率的に行われ、小規模なAIモデルの事前学習や追加学習などの比較的軽量な処理に対して、単一のデータセンタと遜色ない性能を発揮できる。これによって、複数のデータセンタ環境で柔軟にGPUクラスタを構築し、効率的なリソース利用を実現することが可能だ。
・NVIDIA NeMo
分散学習に対応した大規模言語モデルの学習、カスタマイズ、展開のためのエンド・ツー・エンド プラットフォームであるNVIDIA NeMoが活用された。今回の実証で扱ったLlama 2 7B以外のモデルなど、将来的に様々な生成AIの処理に対応可能だ。
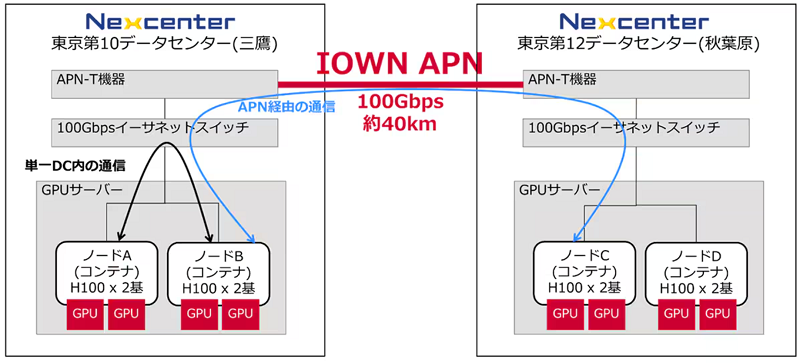
実証のイメージ
本実証の成果
本実証は世界で初めて、高速大容量・低遅延な接続を可能とするIOWN APNとNVIDIA NeMoを組み合わせた環境で、生成AIのモデル学習(Llama 2 7Bの事前学習)を動作させることに成功した。
単一のデータセンタで学習させる場合の所要時間と比較して、インターネット経由の分散データセンタでは29倍の時間がかかるが、IOWN APN経由の分散データセンタでは1.006倍と、単一のデータセンタとほぼ同等の性能を発揮できることを確認したという。
今後の展開
NTT Comは「本実証の成果をもとに、IOWN APNで接続された分散データセンタにおけるGPUクラスタの可能性をさらに広げ、国内70拠点以上のデータセンタ間などを接続可能な『APN専用線プラン powered by IOWN』や、液冷方式サーバに対応した超省エネ型データセンターサービス『Green Nexcenter』、などを組み合せたGPUクラウドソリューションとしてお客さまへ提供をめざす」としている。



