エッジコンピューティング環境を想定した非同期分散型深層学習の実現【NTT】
データセンタ/LAN 無料大量のデータを多サーバに分散蓄積したままでも、モデル学習を可能にする技術
NTTは8月24日、エッジコンピューティング上の機械学習を想定した非同期分散型深層学習技術(Edge-consensus Learning)を実現したと発表した。
現在の機械学習、特に深層学習では、1か所(クラウド)にデータを集約し、画像/音声認識等のモデルを学習することが一般的だ。しかし、あらゆるモノがネットワークに接続するIoT時代において、膨大なデータをクラウドに集約することは困難となる。また、プライバシー保護の観点で、データをローカルにあるサーバ/機器にとどめたいという需要も増加している。関連して、EUの一般データ保護規則(GDPR)のようなプライバシー保護のための法的規則も強化されつつある。こうした時代において、データを蓄積・分析・処理するサーバを分散化し、上位システム(クラウド)や通信網の処理負荷を低減させ、応答速度やプライバシー保護の観点でユーザの利便性を高めるエッジコンピューティングへの期待が高まっている。
同研究の目的は、エッジコンピューティングのように分散配置されたサーバ群に分散してデータが蓄積されていく環境でも、あたかも一か所にデータを集約して学習したかのようなグローバルモデルを得るための学習アルゴリズムを開発することだ。今回開発された技術は、(1)統計的に非均一なデータがサーバ群に蓄積されていて、 かつ(2)サーバ群がモデルに関連する変数を非同期に通信/交換していても、全部のデータを1か所に集めて学習したのと同等のモデルを得られることを確認したという点で、学術性/実用性が共に高い学習アルゴリズムだと言える。
今回の成果は、アメリカ計算機学会(ACM)主催の国際会議KDD 2020(Knowledge Discovery and Data Mining、採択率16.9%。8/23から開催)にて発表予定だという。また、同成果についての多角的な検証を目的に、関連したコードをGithubにて公開予定だとしている。
研究の背景
現在の機械学習、特に深層学習では、1か所にデータを集約し、1か所でモデルを学習するのが一般的だ。しかし、データ量の激増やプライバシー保護の観点から、近い将来データは分散蓄積されるようになる。例えば、エッジコンピューティング構想では、データ蓄積や処理の負荷分散が提唱されており、EUのデータ保護法的規制GDPRでは、国を跨ぐデータの移送に制限をかけていたり、最小限のデータ収集を要請する条項も存在する。
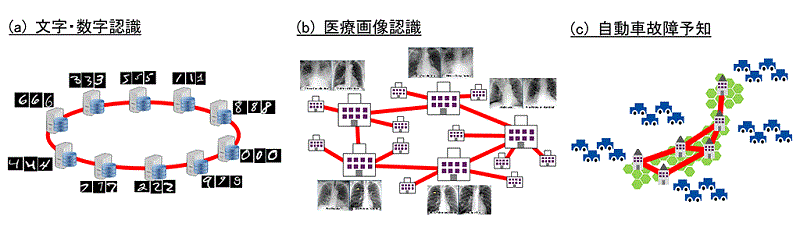
エッジコンピューティング環境で想定されるアプリケーション例と分散データ蓄積。
技術のポイント/特徴
今回開発された学習アルゴリズムは、複数のサーバに異なるデータが分散して蓄積される状況でも、サーバ間で合意形成されたモデルを得ることができる。データの代わりに、モデルに関連する変数をサーバ間で非同期に通信/交換することで、合意形成されたモデルを得る。具体的には、下図に示すように、各サーバ内で行う処理(U)とサーバ間で変数を交換する(X)の2つを交互に繰り返す学習アルゴリズムになっている。
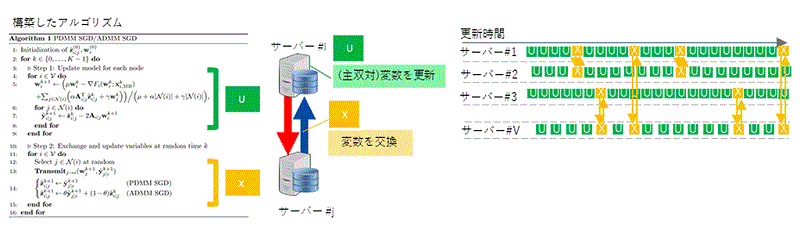
開発された非同期分散型の学習アルゴリズム(Edge-consensus Learning)。
このアルゴリズムの有効性を検証するために行ったシミュレーション実験の結果は次の通り。
8台のサーバがリング状に接続されたネットワークを想定。テスト用の画像データセットとして、一般的に用いられる物体画像認識用のデータセット(CIFAR-10)を用いている。これは、計10個のクラス(航空機、自動車、鳥、猫など)に分類可能な大量の画像で構成されている。一方、同実験では、各サーバ上に統計的に非均一となるように画像を与える。具体的には、各サーバにはそれぞれ10クラスのうち、ある5クラス分のデータのみを与える(ただし、8台合わせると全てのクラスがほぼ均等に存在するデータセットとなる)。NTTは「サーバ群が非同期に通信する状況をシミュレートした結果、提案法を用いると、あたかも一か所にデータを集約して学習したかのようなモデル(グローバルモデル)が得られることを確認した」という。
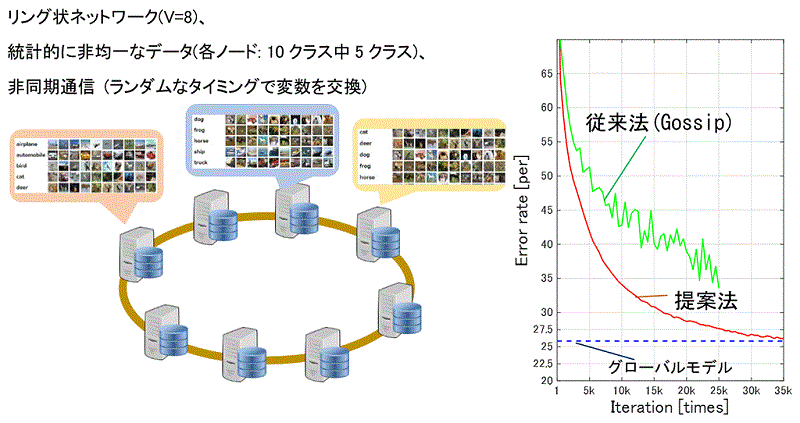
実験結果(抜粋)。一か所にすべてのデータを集約して一か所で学習した結果(青)と性能が一致するモデルを得られるのかを検証するための実験。従来法(緑)を用いた場合は学習が不安定となるが、提案法を用いた場合は安定して学習が進み、グローバルモデルに極めて近いモデルが得られる。
今後の展開
NTTは今後の展開について「エッジコンピューティングを活用した大規模なAI応用が期待される分野での実用化をめざして、パートナーと連携しながら研究開発や実証実験を今後も継続していく。コード公開を通じて、同技術の更なる発展、アプリケーションに関するコラボレーションを促進していく」との考えを示している。



